前文”信息过载时代,我的漏斗式阅读工作流”中,我详细描述了信息处理的漏斗式工作流:从信息源的广泛采集,到聚合池的稳定汇聚,再到预处理、AI 精选、精读留存和个人画像的完整链路。这套流程的核心理念是分层处理——并非所有信息都值得投入时间精读,也并非所有信息都值得长期留存。
但理念落地到工程层面,中间有大量”必要却繁琐”的预处理工作:RSS抓取、全文补全、噪音过滤、内容去重、质量评估、摘要生成、事件聚合、日报编排…这些环节如果靠手工或零散脚本拼凑,维护成本会随信息源数量线性增长,最终拖垮整套工作流的可持续性。
Infinitum 就是为了解决这些问题而诞生的。它是一个自托管的 RSS 资讯聚合工作台,目标不是替代阅读,而是将漏斗工作流中”中游稳定”和”下游精准”两个关键层的预处理能力进行工程化落地,让我们把精力留给真正需要判断的环节。

产品定位
在漏斗式工作流中,Infinitum 承担的是编排层与预处理层的角色。
它不是另一个 RSS 阅读器,也不是一个 AI 替读文章的工具。它更像是一个信息加工厂:原材料是各路 RSS 源的原始条目,成品是经过清洗、补全、分析和聚合的结构化内容,最终以精选日报的形式输出。
用户不需要逐条阅读进入 Infinitum 的内容。系统会自动完成以下工作:
- 自动补全 RSS 摘要内容为完整正文
- 过滤低质量和黑名单内容
- 为每篇文章生成翻译、摘要和质量评分
- 将描述同一事件的多篇文章聚合为事件簇
- 从事件簇中提炼出结构化的每日精选日报
用户只需要在最后环节做判断:哪些事件值得深入关注,哪些内容值得存入长期知识库。

核心能力
Infinitum 的核心能力是一条从信息采集到日报输出的完整处理链路。
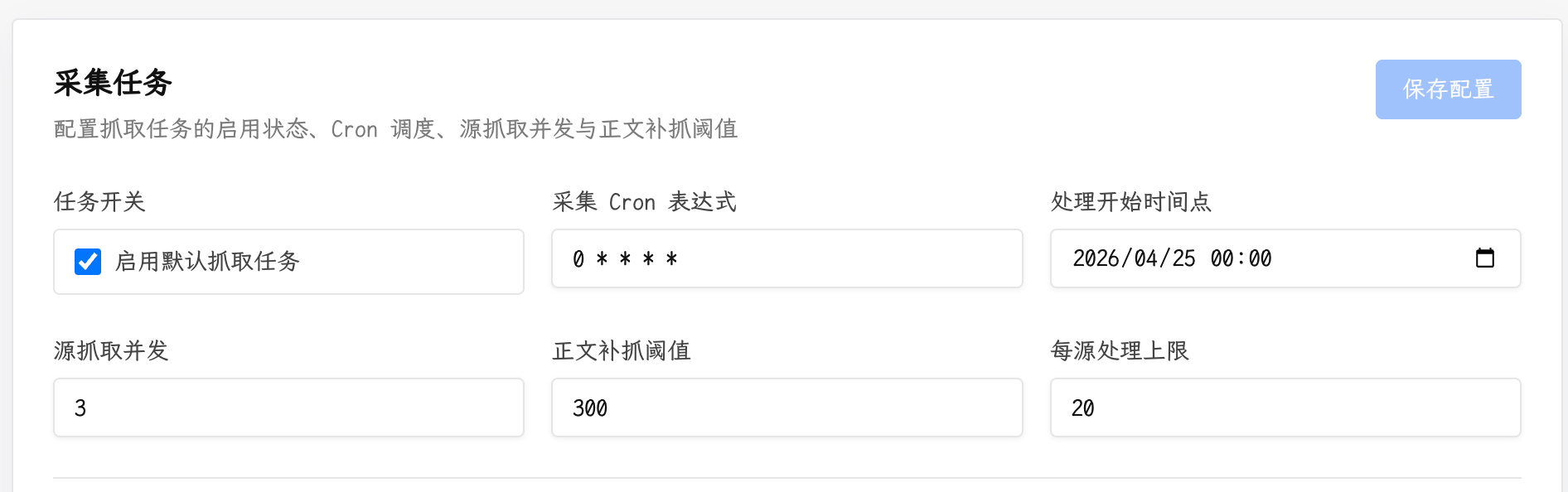
1. 智能采集与全文补全
RSS 源的原始内容质量参差不齐,很多源只提供摘要,甚至只有标题。如果直接把这些半成品交给下游处理,效果会大打折扣。
Infinitum 在采集环节做了几件关键的事:
- 并发抓取:支持多源并行同步,且每个源独立控制并发数和条目上限,避免单一源拖慢整体速度
- 全文补全:当 RSS 内容不足时,自动通过正文提取引擎获取完整文章内容
- 增量更新:基于 ETag/Last-Modified 的条件请求和内容哈希去重,避免重复抓取已处理过的内容
- 过滤与审核:黑名单关键词过滤、低信号标题/URL检测、正文质量评估,被过滤的内容进入审核队列而非直接丢弃
将这些能力组合后,系统保证上游信息源可以多种多样,但内容进入系统后,质量必须统一达标。
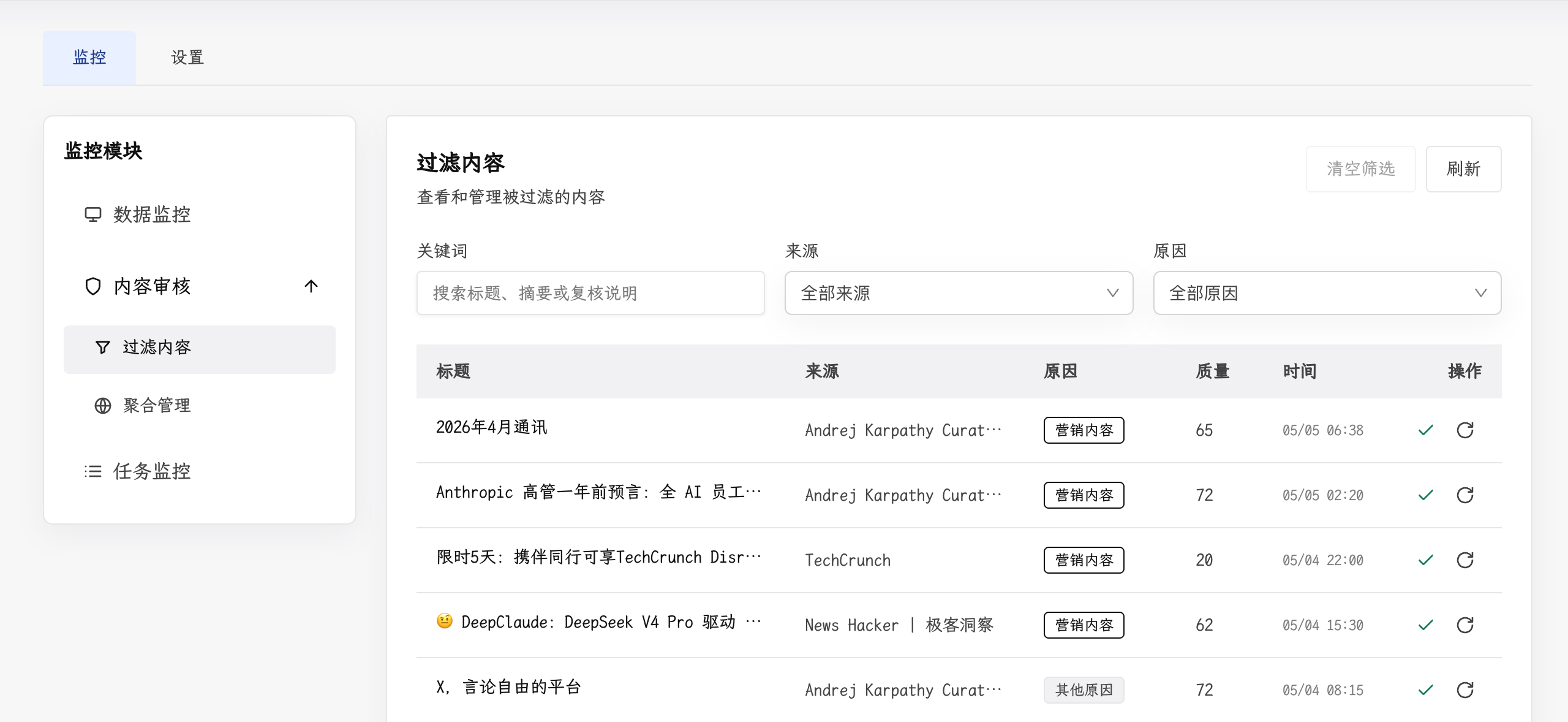
2. AI 深度分析
预处理完成后,每篇文章都会经过 AI 分析层的加工。为后续筛选和聚合提供结构化的判断依据:
- 标题翻译:自动识别非中文标题并翻译,支持重试机制
- 摘要生成:为每篇文章生成简明摘要,降低初步判断的认知成本
- 质量评分:0-100 分的内容质量评估,附带评分理由,帮助快速识别高价值内容
- 事件分析:提取结构化的事件信息,包括事件类型、主体、动作、客体和日期等,为后续的事件聚合奠定基础
每个 AI 任务可以绑定不同的模型和 API 配置,并内置熔断降级机制,确保单个模型异常不会阻塞整条流水线。

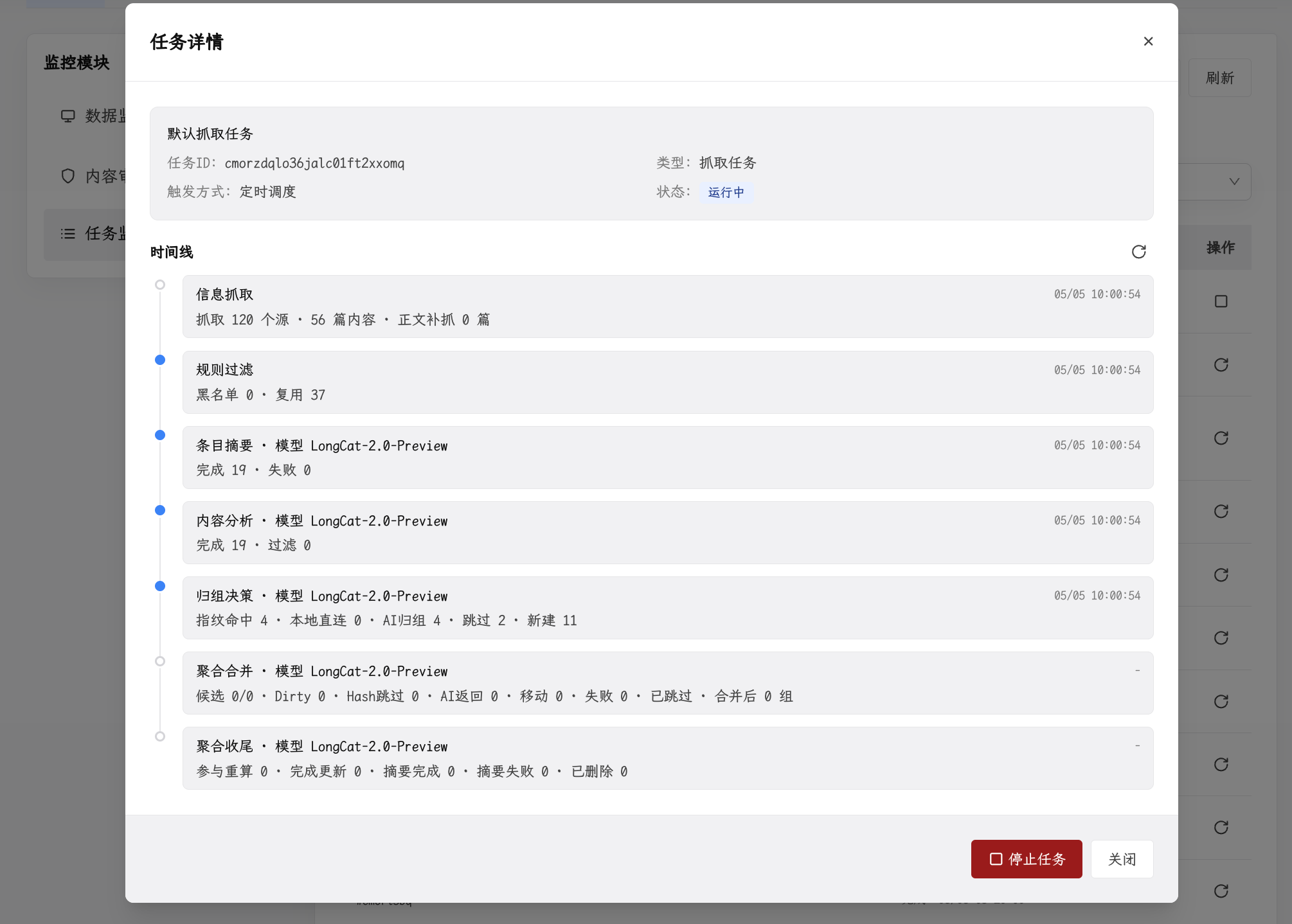
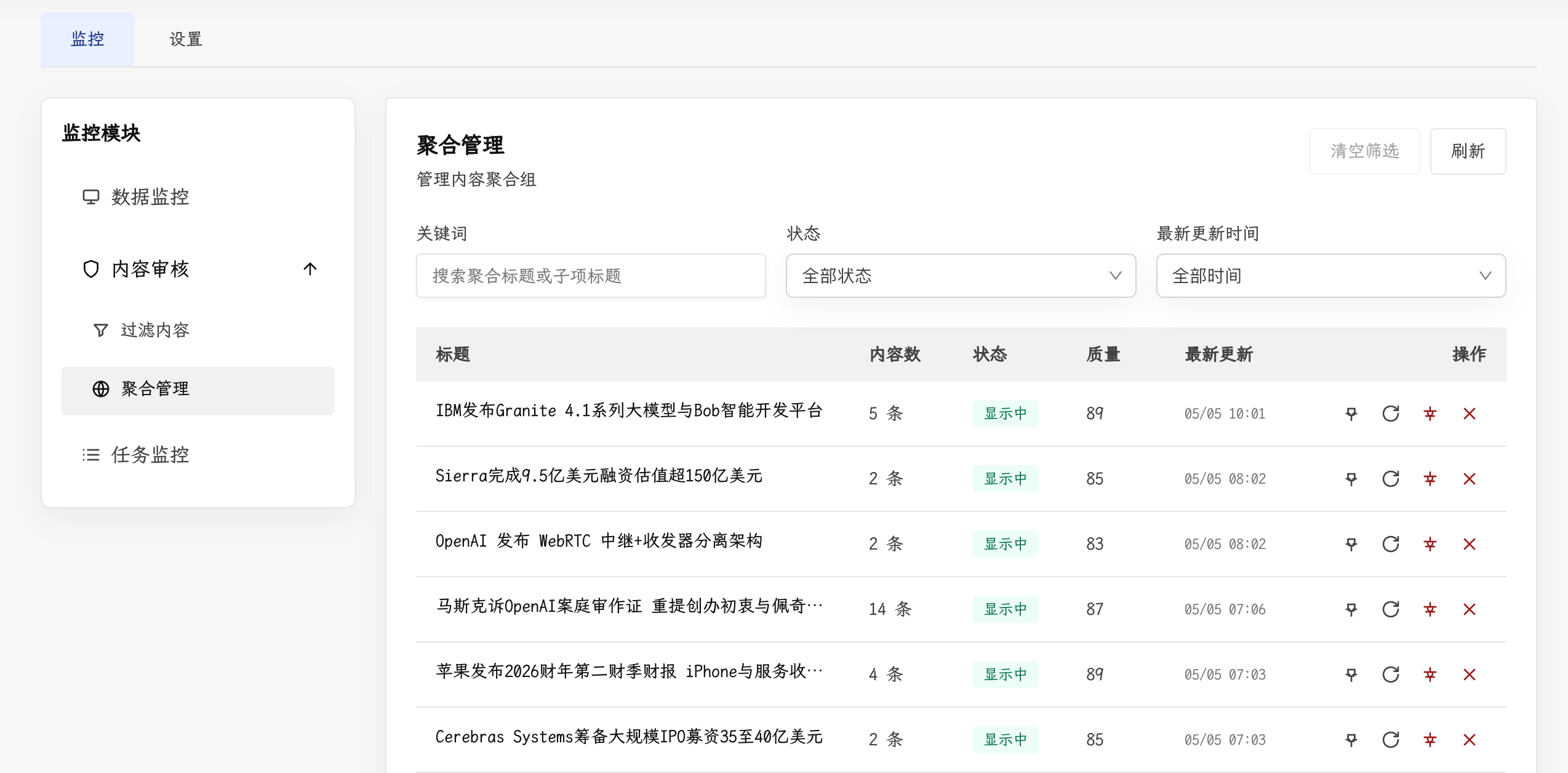
3. 事件聚合
这是 Infinitum 区别于普通 RSS 工具的核心能力之一。
同一个重要事件,往往会被多家媒体报道。如果不做聚合处理,用户在浏览时会反复看到同一事件的不同版本,既浪费时间又增加认知负担。
Infinitum 通过三层匹配策略将描述同一事件的多篇文章聚合为”事件簇”:
- 指纹精确匹配:将完全重复的内容直接归组
- 基于特征的快速匹配:通过评分排序快速判断两篇文章是否描述同一事件
- AI 辅助匹配:对难以判断的候选内容,由 AI 进行最终裁决
此外,系统会在每次采集完成后,对近 7 天的事件簇进行合并检查,确保同一事件在多次采集中最终被汇聚在一起。且每个事件簇都会自动生成聚合摘要,避免用户重复阅读。

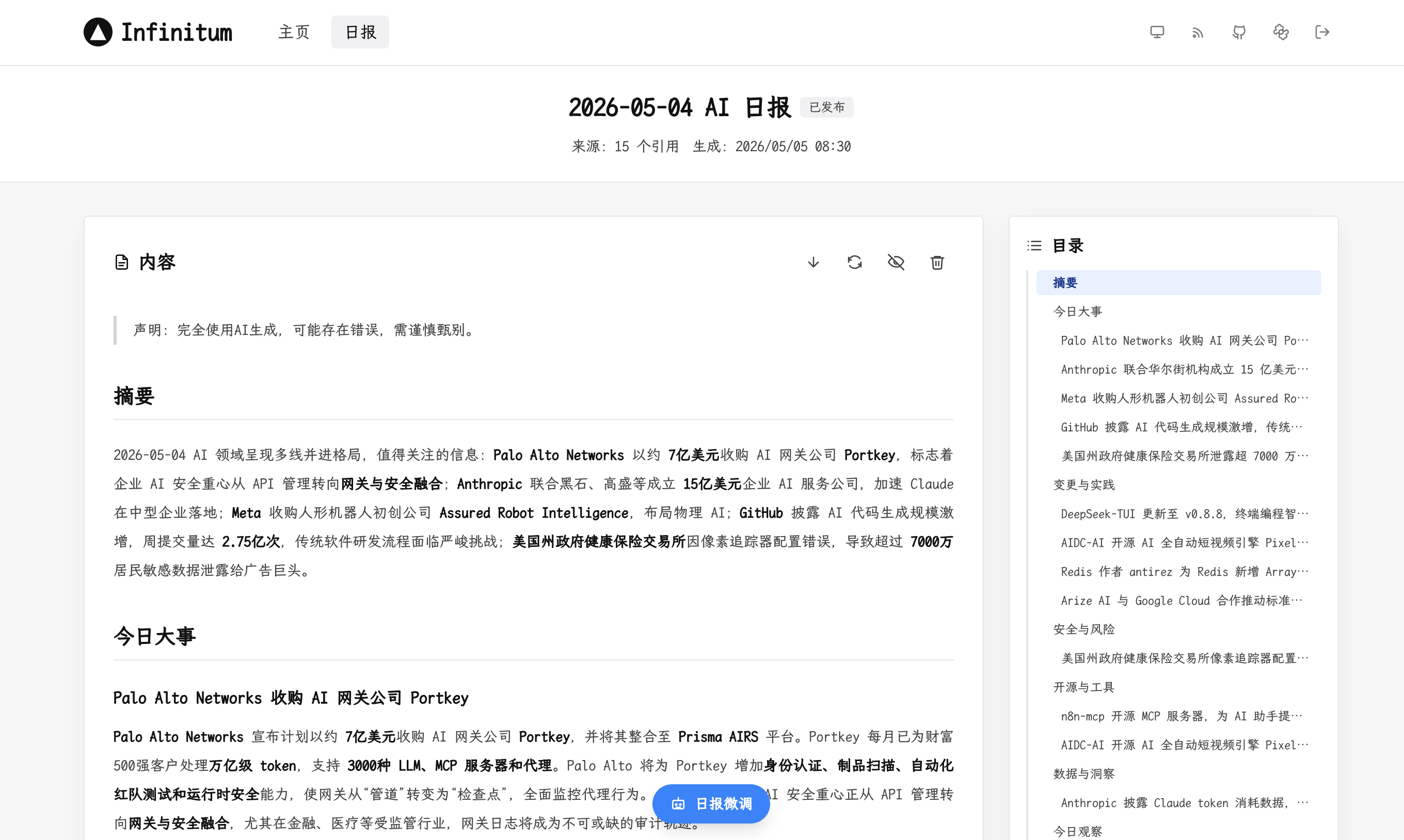
4. AI 日报生成与迭代
事件聚合完成后,Infinitum 会从当天的候选内容中生成结构化的 AI 日报——一份经过筛选和编排的信息产品:
- 自动去重:与近 7 天的日报进行比对,避免反复报道同一事件
- 草稿/发布流程:支持先生成草稿、人工审阅后再发布,也支持全自动发布
- AI 辅助迭代:提供对话式和结构化两种迭代模式,可以在日报生成后继续与 AI 对话调整内容
- 源召回:迭代过程中可以搜索并补充额外的信息源
- Markdown 导出:已发布的日报支持导出为 Markdown 格式,方便继续用于周报、专题写作等场景

5. 公开 Feed 与互动
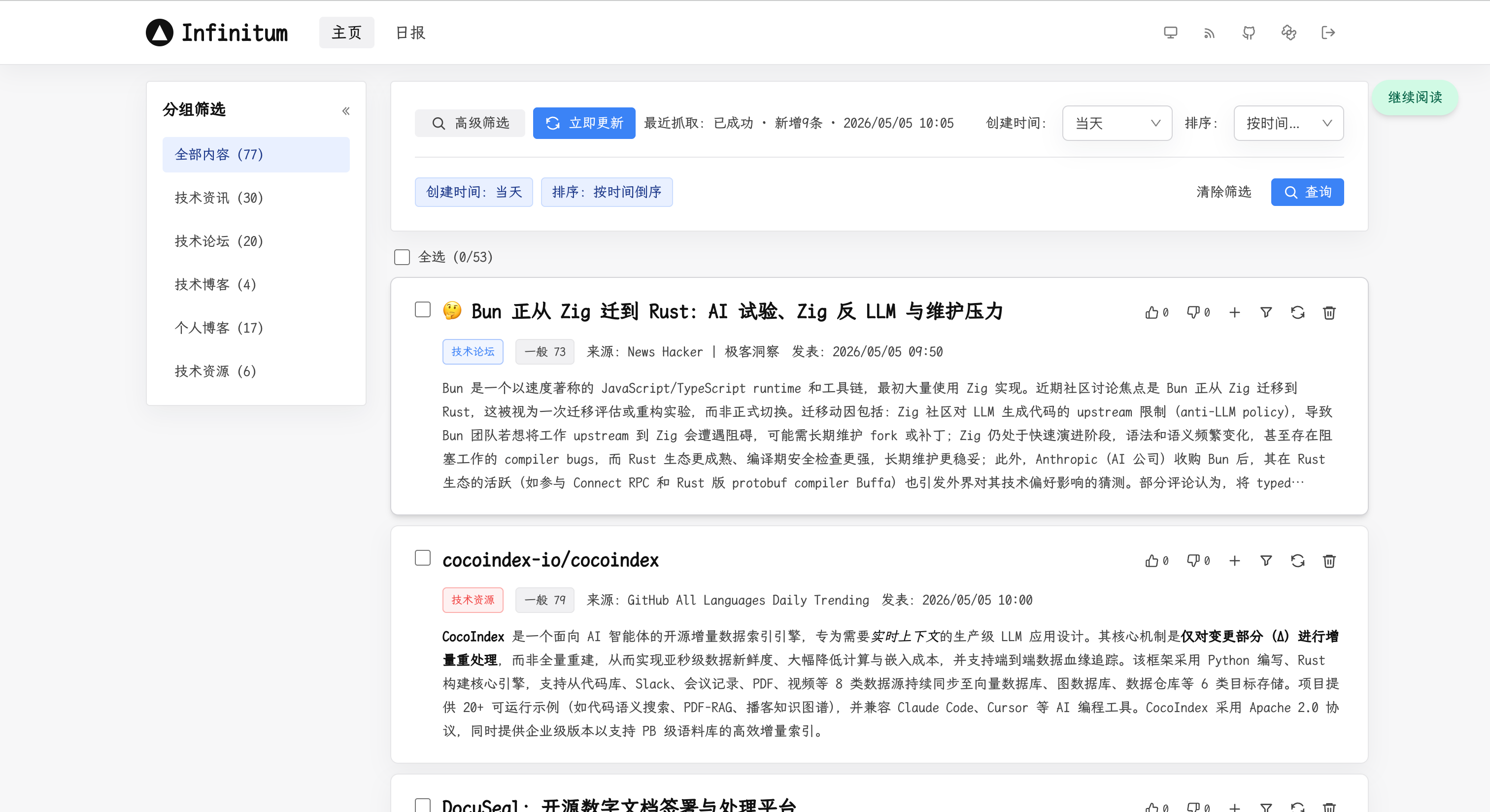
Infinitum 也提供了面向外部的信息输出能力:
- 公开 Feed 浏览:支持按时间、来源、分组、关键词等维度筛选浏览(演示站点:https://infinitum.shawnxie.top)
- 推荐排序:除时间排序外,还支持基于推荐算法的智能排序
- 访客投票:访客可以对事件簇进行投票,形成社区驱动的内容信号
- 公开 RSS 输出:通过
/api/feed/rss提供标准化的 RSS 订阅,可以被其他 RSS 阅读器消费(更多查看订阅源使用说明)
懒人阅读方案 2.0
在之前的”懒人阅读方案”中,我分享了一套基于 FreshRSS + Readrops + flomo 的碎片化阅读流程。那套方案解决了信息统一采集和移动端阅读的问题,但在预处理和信息筛选环节仍依赖人工。
现在,随着 Infinitum 和 ReadropsForLumina 的成熟,懒人阅读方案迎来了 2.0 版本——在保留原有碎片化阅读体验的同时,大幅增强了上游的信息处理能力。
整体架构
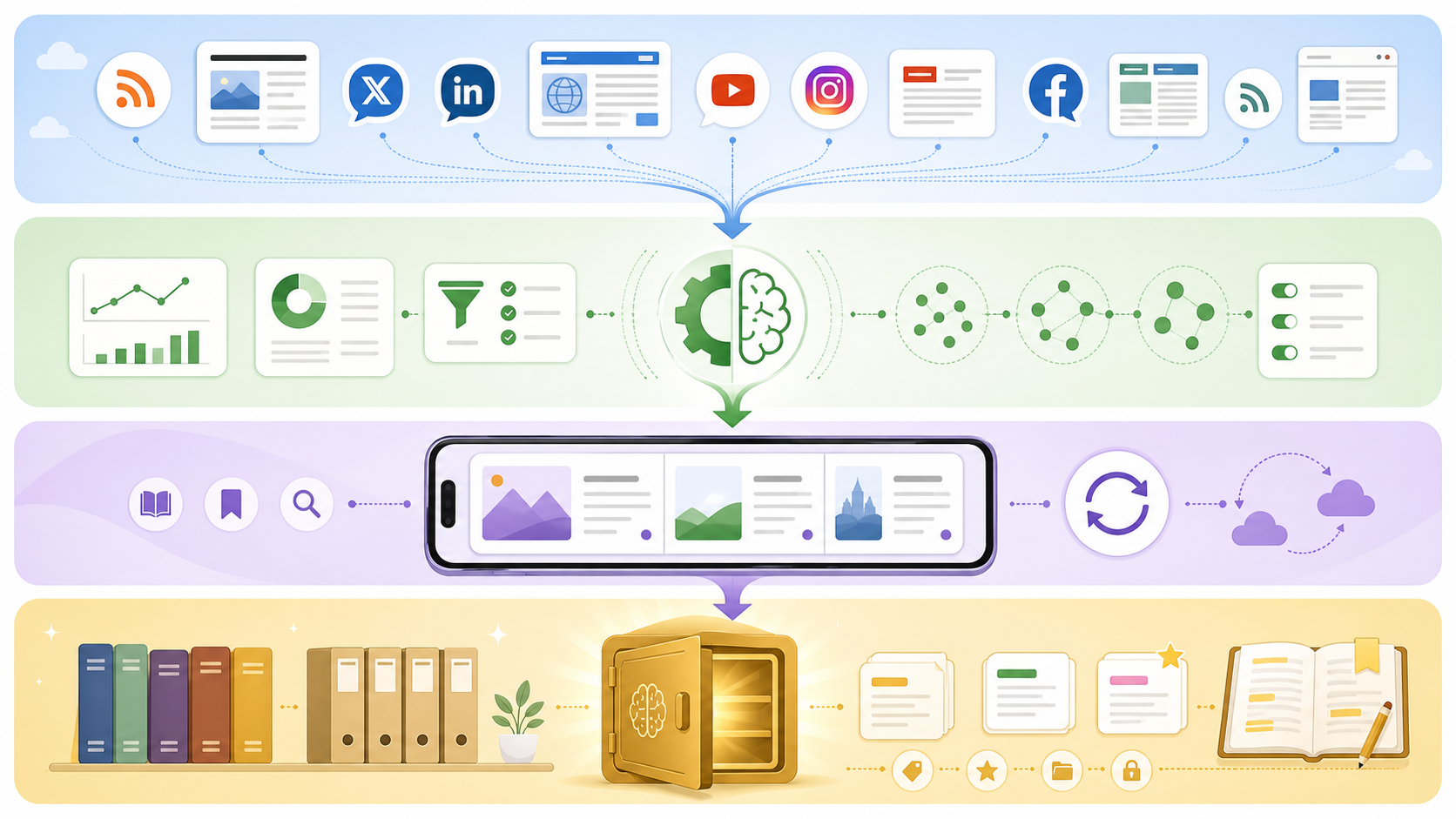
懒人阅读方案 2.0 的核心思路是:Infinitum 负责”想”,ReadropsForLumina 负责”读”,Lumina 负责”留”。整套链路分为四个层次:
第一层:信息源 → Infinitum
所有 RSS 信息源统一接入 Infinitum。Infinitum 自动完成抓取、全文补全、AI 分析、事件聚合和日报生成。不再需要逐条浏览原始 RSS 内容,而是直接阅读经过预处理的高质量 Feed 或每日精选日报。
第二层:Infinitum 公开 Feed → ReadropsForLumina
Infinitum 提供公开 RSS 输出接口,ReadropsForLumina 将其作为订阅源接入。这样在手机端,看到的不再是未经筛选的原始信息流,而是 Infinitum 已经处理过的内容。配合 ReadropsForLumina 的多服务支持(FreshRSS、Nextcloud News、Fever 等),可以将 Infinitum 的输出和原有的 RSS 订阅源统一在一个阅读界面中。
第三层:碎片化阅读 → 判断与筛选
在 ReadropsForLumina 中,利用碎片时间进行浏览。遇到值得深入关注的内容,直接通过内置的”同步到 Lumina”功能一键推送。ReadropsForLumina 还支持接收从其他应用分享的链接,再转发到 Lumina,覆盖了在微信、浏览器等场景中发现好文章的情况。对于微信公众号文章,ReadropsForLumina 会自动打开 WebView 抓取全文内容后再上传,确保进入 Lumina 的是完整内容。
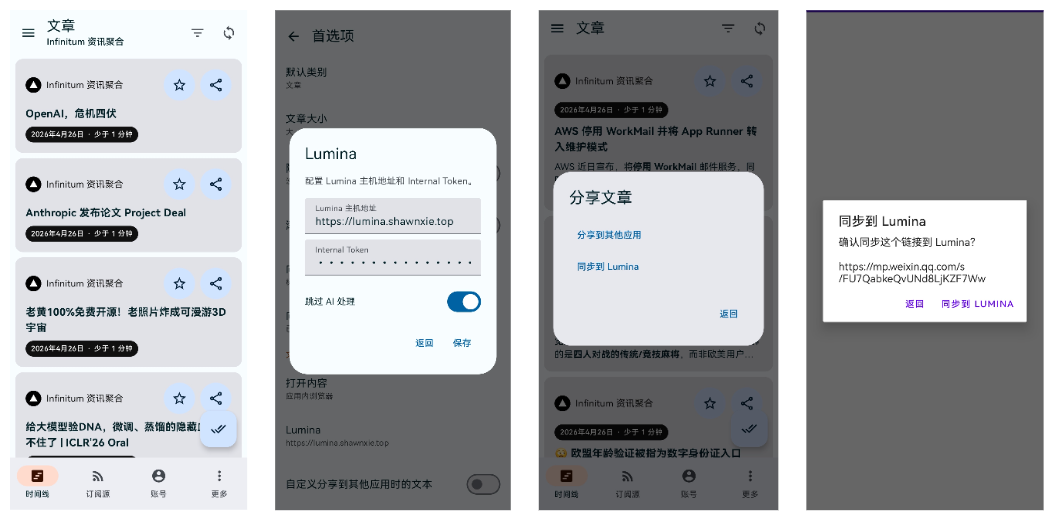
第四层:Lumina → 长期沉淀
进入 Lumina 的内容,可以借助 AI 辅助理解(摘要、大纲、翻译、信息图)快速建立认知框架,再通过精读、批注和标记完成深度加工。沉淀下来的内容形成个人知识库,支持导出、回顾和后续输出。
相比 1.0 方案的核心升级
| 能力维度 | 1.0 方案 | 2.0 方案 |
|---|---|---|
| 信息预处理 | 人工逐条浏览筛选 | Infinitum 自动完成去重、补全、分析、聚合 |
| 内容质量控制 | 依赖信息源质量 | AI 质量评分 + 黑名单过滤 + 审核队列 |
| 重复内容处理 | 人工识别 | 事件聚合自动合并同一事件的多篇报道 |
| 每日精选 | 无 | Infinitum 自动生成结构化日报 |
| 移动端阅读 | Readrops 原版 | ReadropsForLumina,支持一键同步到 Lumina |
| 长期沉淀 | flomo 卡片笔记 | Lumina 知识库,支持 AI 辅助理解、精读批注 |
| 信息闭环 | 弱 | Infinitum 公开 Feed 可被再次订阅,形成循环 |
写在最后
懒人阅读方案从 1.0 到 2.0 的演进,本质上是同一思路的工程化升级:系统承担更多可自动化的预处理工作,人则专注于不可替代的价值判断。
1.0 方案解决了信息采集和碎片化阅读的问题,但预处理和筛选仍然依赖人工。2.0 方案通过 Infinitum 补上了这一环,ReadropsForLumina 则在移动端延续了流畅的阅读体验,并打通了向 Lumina 知识库的一键沉淀通道。
整套链路的信息流是:信息源 → Infinitum(预处理与聚合)→ ReadropsForLumina(碎片化阅读)→ Lumina(深度加工与长期沉淀)。
每个环节各司其职,这正是漏斗式工作流的核心思想——分层处理。让信息在漏斗中自然收窄,让真正重要的内容被看见。